
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- #미국환율
- 컨티뉴언
- #Snp500
- #엔비디아주가
- #ai관련주
- 도서리뷰
- 책리뷰
- 일상
- 책추천
- #메타주가
- #미국증시
- #테슬라주가
- #엔비디아실적발표
- #인공지능
- 도서
- #애플주가
- #책추천
- #도서리뷰
- 책
- #미국주식
- #금리
- 돈
- 부자
- #엔비디아주식
- #엔비디아
- 독서모임
- #반도체관련주
- 공부
- #엔비디아관련주
- 독서
- Today
- Total
기록하는 투자자
실무로 통하는 ML 문제 해결 with 파이썬, 기본부터 쉽게 익히고 싶다면? 본문
- 저자
- 카일 갤러틴, 크리스 알본
- 출판
- 한빛미디어
- 출판일
- 2024.04.29
안녕하세요, 기술과 함께 사는 컨티뉴언입니다.
지금 바로 볼 책은 <실무로 통하는 ML 문제 해결 with 파이썬>인데요.
이 책은 앞으로 실용 가이드라고 해볼게요.
이 실용 가이드는 업무에서 직면할 수 있는
머신 러닝 문제를 해결하는 데 도움이 되는
200개 이상의 독립적인 레시피를 제공하는데요.
파이썬과 판다 및 사이킷-러닝을 포함한
라이브러리에 익숙하다면 데이터 로드부터 모델 훈련,
신경망 활용에 이르기까지
특정 문제를 해결할 수 있을거예요.
바로 시작합니다!

이번 업데이트 버전의 각 레시피에는
토이 데이터 세트로 복사, 붙여넣기, 실행하여 작동하는지
확인할 수 있는 코드가 포함되어 있는데요.
여기에서 사용 사례나 애플리케이션에 따라
이러한 레시피를 조정할 수 있어요.
레시피에는 솔루션을 설명하고 의미 있는 맥락을
제공하는 토론이 포함되어 있습니다.
이론과 개념을 넘어 실제 작동하는
머신 러닝 애플리케이션을 구축하는 데 필요한 핵심을 배워보세요.
다음에 대한 레시피를 찾을 수 있어요.
● 벡터, 행렬, 배열
● CSV, JSON, SQL, 데이터베이스, 클라우드 스토리지 및 기타 소스 데이터로 작업하기
● 수치형과 범주형 데이터, 텍스트, 이미지, 날짜, 시간 다루기
● 특성 추출 또는 특성 선택을 사용한 차원 축소
● 모델 평가와 선택
● 선형 회귀, 로지스틱 회귀, 트리, 랜덤 포레스트, k-최근접 이웃
● 서포트 벡터 머신(SVM), 나이브 베이즈, 군집, 트리 기반 모델 지원
● 훈련된 모델의 저장, 로드 및 서빙


저는 팬데믹 기간 동안 데이터 과학을 공부해왔는데,
대학을 졸업한 지 오래되어서 그런지
제 두뇌가 원하는 만큼 분석적으로 날카롭지 못했던거죠.
다른 많은 사람들과 마찬가지로
저도 그동안 공부한 내용을 보충하기 위해
인터넷을 샅샅이 뒤졌습니다.
여러 사이트를 찾아보았지만
Chris의 웹사이트는 거의 모든 코드에 대한 적절한 설명과 함께
가장 체계적이고 명쾌하게 정리되어 있어 따라하기 쉬웠습니다.
따라서 각 연습 문제가 명확하게 설명되어 있습니다.
저는 항상 인터넷에 접속할 수 있는 상황이 아니라는 것을 깨닫고
책을 보기로 결정했습니다.
기계 학습에 대해 잘 모르는 사람들을
도와주는 Chris에게 더 큰 박수를 보내봅니다!
쿡북 스타일의 이 책은 하나의 레시피가 특정 메서드나 클래스의 사용 방법을 다룹니다


크리스 알본은 데이터 과학에 대한
폭넓고 깊은 지식을 가지고 있는데요.
이 책은 머신 러닝에서 Python과 Pandas를
비롯한 관련 라이브러리를 사용하기 위한
힌트, 설명, 예제가 가득한 보물 같은 책인데요.
텍스트는 아니지만 치트 시트 그 이상인거죠.
Chris는 배열, 벡터, 행렬의 로드, 정렬, 검사,
분석, 결합, 수정, 변환 등 일반적인 연산부터 시작합니다.
그런 다음 데이터 처리, 정규화, 표준화, 범주 인코딩,
날짜 범위 선택, 차원 축소, 기능 선택, 교차 검증 등
데이터 준비에 사용되는 절차를 이어가는데요.
여러 장에서는 모델 선택, 하이퍼파라미터 조정,
성능 메트릭, 피팅 및 유효성 검사에 대한
논의를 포함하여 모델을 검토하는거죠.
이제는 머신러닝과 딥러닝 실무자들의 요구를 충족시킬 수 있는 최신 파이썬 라이브러리를 활용한
실용적인 콘텐츠가 필요하게 되었습니다


각 주제는 명확하게 설명되어 있으며,
짧은 독립된 Python(버전 3) 프로그램 목록이 예시로 제공되는데요.
명령이나 프로시저와 관련된 빠른 복습이 필요한
모든 분들께 이 책을 적극 추천드려요.
이 책은 각 함수를 이해하기 쉬운 예시를 들어
설명하는 것으로 시작하고 있어요.
하지만 책이 계속 진행됨에 따라 이러한 부분을 기반으로 구축됩니다.
접근 방식은 잘 훈련되어 있으며 빠르게 솔루션을 구축할 수 있는거죠.
후자에 중점을 둔 이론과 코드가 혼합되어 있어요.
미적분을 배우지는 않지만 코드에서
미적분을 수행하는 방법을 배우게 되는데요.
앤드류 응의 강좌를 듣는 분들과
결과를 원하는 분들에게 좋습니다.
파이썬과 판다스,
사이킷런을 포함한 라이브러리에 익숙하다면
데이터 로드부터 모델 훈련,
신경망 활용에 이르기까지
특정 문제를 해결할 수 있습니다.
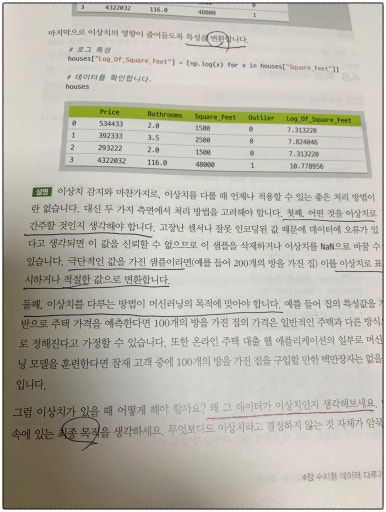

이 책은 유용하지만 컴퓨터에 따라 코딩 오류가 있을 수 있어요.
코딩을 완전히 처음 접하는 사람에게는 추천하지 않지만
디버깅에 자신 있는 사람(일반적으로 오류가 적기 때문에)에게는 유용한데요.
저자의 깃허브 계정에 있는
일부 데이터 파일은 언급되지 않았어요.
이때 사용 사례나 애플리케이션에 따라
이러한 레시피를 조정할 수 있습니다.


이 책은 특히 데이터 과학 분야에서
1~2년 이상의 경력을 가진 사람이 아닌
초보자를 위한 책인데요.
이 책은 많은 정보로 구성되어 있지만
포괄적이지 않기 때문에 따르는 것을
권장하지 않는데요.
이 책에는 몇 가지 중요한 개념과 응용이 누락되어 있으며,
그 대신 쉽게 구글에서 찾을 수 있는
불필요한 양의 Python 코드로 대체되어 있는거죠.
이론과 개념을 넘어 실제 작동하는 머신러닝
애플리케이션을 구축하는 데
필요한 핵심을 배워보세요.

'제대로 보는 도서리뷰' 카테고리의 다른 글
| DX 디지털 대전환 시대 AX 인공지능 대전환 AI Home과 UI, UX의 변화는? (0) | 2024.05.29 |
|---|---|
| 큐리어스, 세상의 모든 질문을 하자! (1) | 2024.05.26 |
| 고민도 경력이 되나요? 고민만 하는 시대, 앞으로 어떻게 살 것인가, 김수정, 양봄내음 저자, 포르체 출판사 (1) | 2024.05.23 |
| 김경일의 지혜로운 인간생활(블루캣 에디션) 인간관계, 행복할 수 있을까? (0) | 2024.05.21 |
| 구글 임원에서 실리콘밸리 알바생이 되었습니다, 당신의 전성기는 지금인가요? (3) | 2024.05.21 |



